Gleaning Information from Multiple Haystacks: Unstructured Data Analysis
Written By: An IntelliGenesis Senior All-Source Intelligence Analyst This is what most of our days consist of– large unruly sets of non-sense that we must make sense. Or that used to be the case, more than likely nowadays we are looking at multiple haystacks of data. Some of those will be kind to us and have some form of structure, most will not. It is said that by the year 2020, the amount of digital data will breach 40 zettabytes. We all know some form of structured data–from banking records and medical records to inventory stock lists. The data within each cell for instance will be formatted in a single fashion (think a UPC code or serial number) and it can only ever be that format. Unstructured data on the other hand is structured data’s unruly cousin Eddy. It will contain some bit of information that you need, but it will not be in a well-defined field nor will it be consistently formatted throughout. Now imagine taking the structured data and trying to link it via one of its edges to the table of cousin Eddy data. You would end up just as crazy as Clark.
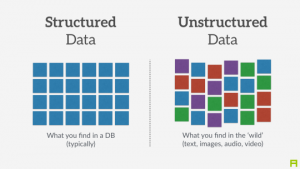
Aside from the obvious disadvantage that having to deal with unstructured data puts an analyst at, there are some other factors that hinder the process–one of those being the three V’s (Volume, Variety, and Velocity). The ever-growing volume of unstructured data can overtake traditional storage systems. The vast variety of unstructured data makes it a management nightmare in trying to corral the data. And then the velocity, the pace at which the unstructured data is ingested or made available. These factors have major impacts on not only the analysis, but the cost of acquiring and storing the data.

Well then, how do we tackle the data to make use of it? There are many approaches, but we don’t have to look too far here at IG to see a real-world example of tackling cousin Eddy, err I mean unstructured data. Our teammates at Traversed have been working on a product called Proximity. You have probably heard it mentioned once or twice, but here is a quick rundown. Lots of unstructured communications moving around the inter-webs have zero geographic metadata associated with it (think Twitter’s tweets when someone has their location disabled). However, within the tweet there is data that may imply time, events, and locations. The data within the tweet is highly unstructured. Different languages, different dialects, the use of emojis and hashtags (#WAYCOOLLINK). They are taking many different approaches and utilizing techniques in Natural Language Processing (NLP), machine learning, and artificial intelligence. By tuning each of these components to process the data, it can then make inferences pertaining to locations, temporal determinations, actions, and potential actors. It is pretty slick and they have a lot of insight into taking on and succeeding at making the unstructured data usable. So if you are trying to take on some unruly data and need a little assist, reach out to them and they may have a trick or two to assist.