
Demystifying AI: What is RAG?
RAG, or Retrieval Augmented Generation, is a technique that enables a large language model (LLM) to access information from external sources.
While LLMs like ChatGPT and Claude are incredibly powerful tools, they can only answer questions based on their specific training data, which has a cutoff date and relies on public information. This means they’re not helpful when it comes to your proprietary data or any information outside their training.
But with RAG, you can customize an LLM with any data you choose, controlling the information the model uses to answer your questions. This allows you to leverage the LLM’s generative abilities without retraining or fine-tuning the model, which are both time-consuming and costly processes and don’t accommodate real-time information.
Think of it in terms of a military analogy. LLMs operate at the big-picture strategy level, fine-tuned models serve at the operational level, and RAG models represent the tactical level.
RAG also helps to limit hallucinations if you tell the model to restrict its answers to the data you’ve provided (assuming, of course, you’re providing legit data).
How Does RAG Work?
The basic components of RAG are retrieval, augmentation, and generation. I’ll bet you didn’t see that one coming.
But what do the terms mean?
- Retrieval means searching for and pulling relevant data from a database based on your question(s);
- Augmentation refers to combining both your question and the retrieved data to form a new prompt to send to the LLM; and
- Generation is when the LLM gives you a response.
In the rest of this article, I’ll explain the RAG process and architecture as simply as possible, which means I might leave out some details. To help you dive deeper, I’ve included links to additional research and articles.
Let’s Get Started!
Before you begin with RAG, you need to set up a database of the information you need to answer your questions. This can be documents, images, audio/video, social media posts, email, etc. This is usually called a knowledge base and it can be fixed or it can be updated either periodically or in real-time.
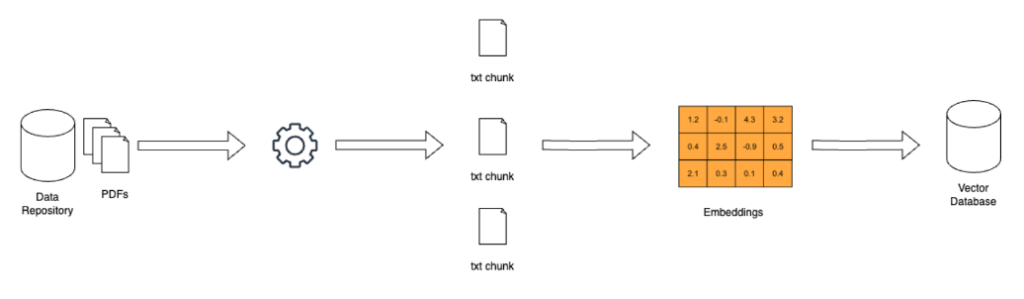
Source: Next-Gen Large Language Models: The Retrieval-Augmented Generation (RAG) Handbook
The data from your knowledge base will be chunked into smaller segments to make processing it more efficient. These chunks are turned into embeddings, or numerical representations that the LLM can understand, and then stored in a vector database. It’s worth noting that the embeddings capture semantic relationships in the data, which produces search results that reflect deeper meaning and context than keyword matching.
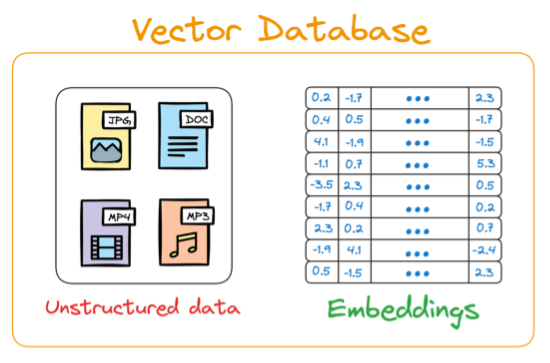
Source: A Beginner-friendly and Comprehensive Deep Dive on Vector Databases
Let the Games Begin
Now that your vector database is set up, you can ask the LLM a question and start the RAG process.
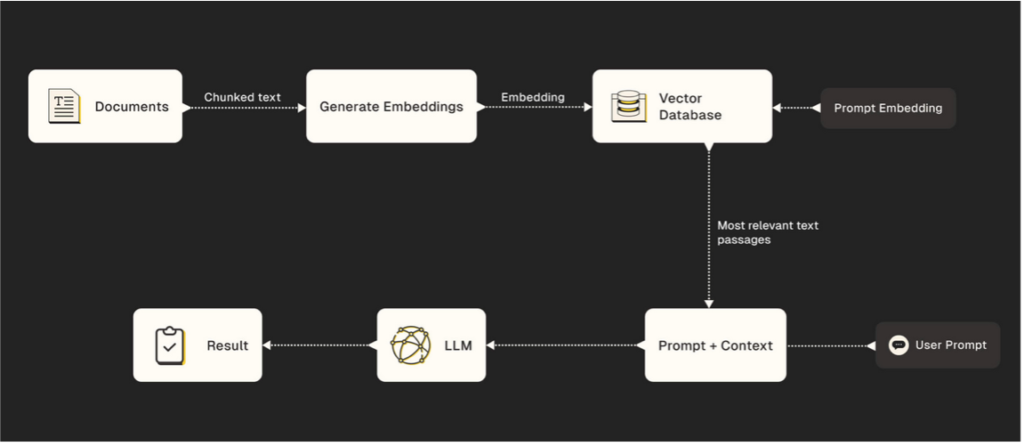
Source: Retrieval Augmented Generation: A Friendly Guide
- (1) The retrieval step begins with embedding your question (query) so that it is compatible with the embeddings in your vector database. Then, the RAG system searches that database looking for semantic similarities between the query embedding and the stored data embeddings. These similarity measurements are based on a distance metric—usually cosine similarity or Euclidean distance—where data points with related characteristics are grouped closer together than those that differ from each other. This allows the RAG model to retrieve the most relevant information for your query.
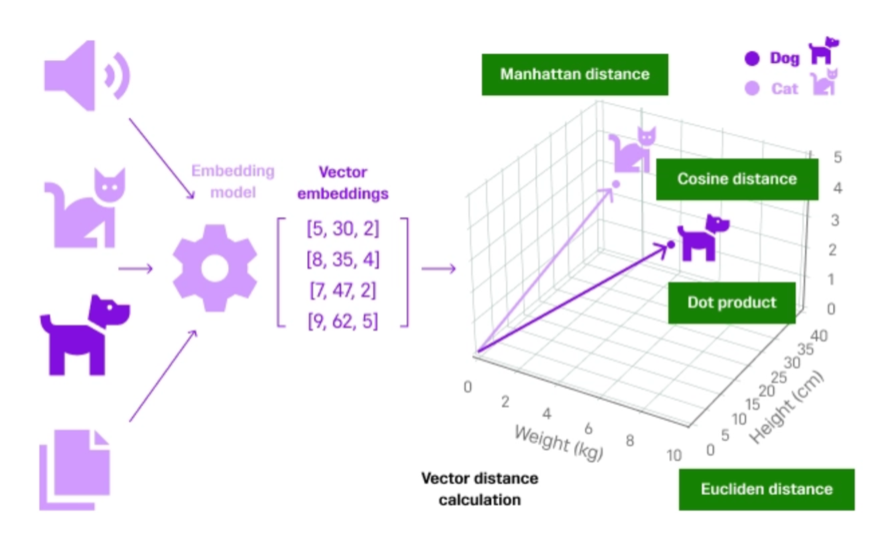
Source: Understanding + Calculating the Distance Between Vectors
- (2) After the data is retrieved, it’s time for the augmentation step. Here, the retrieved information is combined with your original query and sent to the LLM. If your RAG system is well designed, the model is only fed the context it needs to provide an accurate response.
- (3) Lastly, we have the generation step, where the LLM responds to your query based on the information from the retrieval and augmentation steps.
RAG vs. Prompt Stuffing
At this point, you may be wondering why you can’t just paste the data you need into the LLM prompt when you want to ask questions about it. It’s so much easier, right?
As LLM context windows continue to expand, there’s been some debate that “prompt stuffing” could replace RAG.
For background, the context window is the amount of tokens you can include in the input prompt (a token is roughly four characters). ChatGPT-3.5 can only handle about 4,000 tokens, but GPT4o can handle 128,000 and Gemini 1.5 Pro goes to 2 million. Two million tokens is roughly 4,000 pages. That’s a lot!
While recent research has shown some performance advantages with these long context LLMs, they come with significantly higher computational costs. As well, there is the “lost in the middle” phenomena, where LLMs tend to overlook information that’s located in the middle of the content injected into the prompt.
Ultimately, RAG is a more efficient and cost-effective solution because it only retrieves the most relevant information to respond to your question.
Advanced RAG Methods
As RAG grows in popularity, new techniques are emerging to address limitations in the process. I’ll point you to the article “Advanced RAG Techniques: an Illustrated Overview” from December 2023 as a reference. The diagram below, taken from the article, highlights some of the additional methods available to improve the RAG framework.
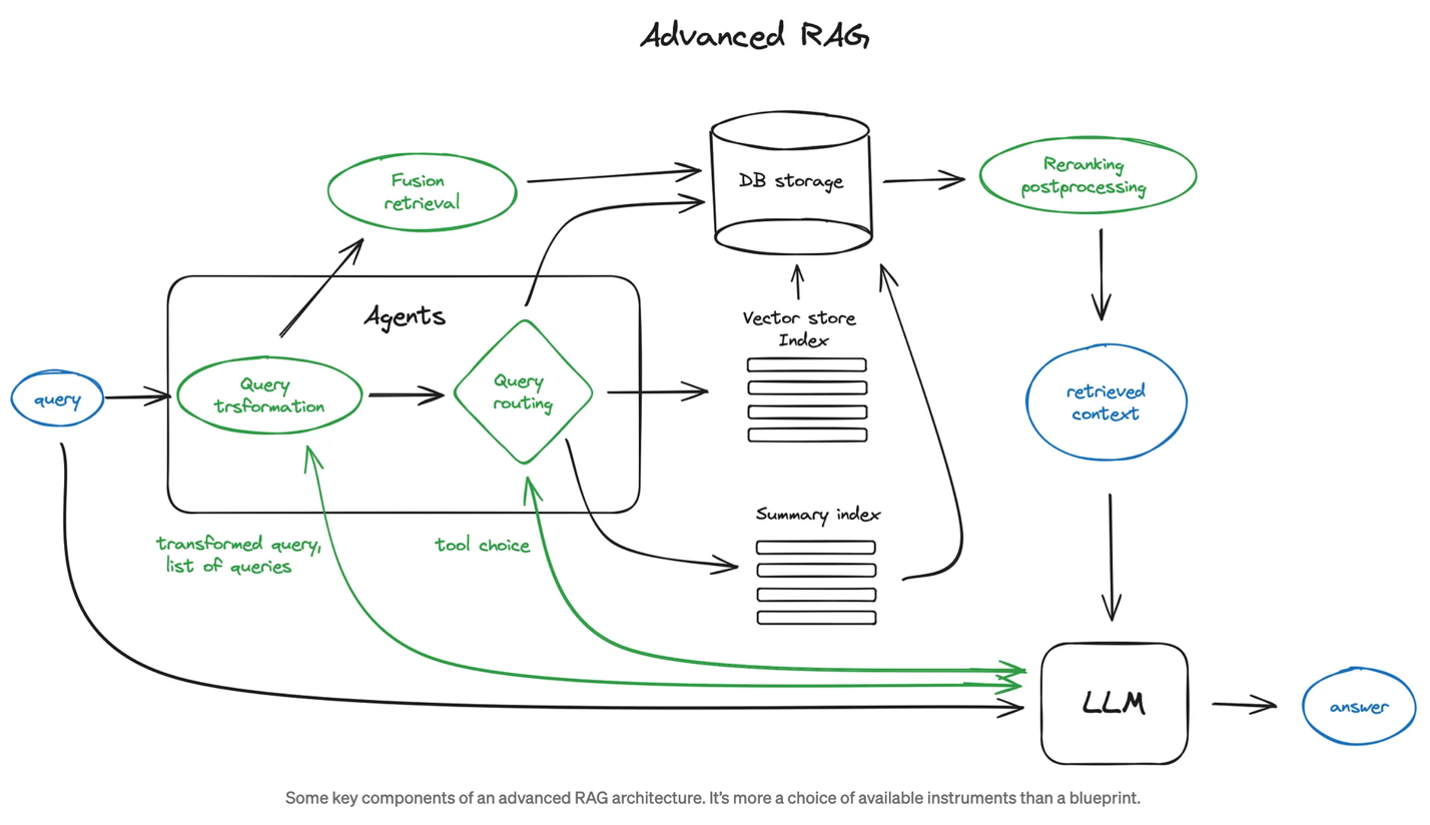
Source: Advanced RAG Techniques: An Illustrated Overview
Graph RAG
While most RAG implementations are currently vector-based, there’s growing interest in incorporating knowledge graphs into the process to capture even deeper and more complex relationships between data points. Knowledge graphs plot these interconnections using nodes and edges.
- Nodes represent entities like people or concepts; and
- Edges are the connections between nodes.
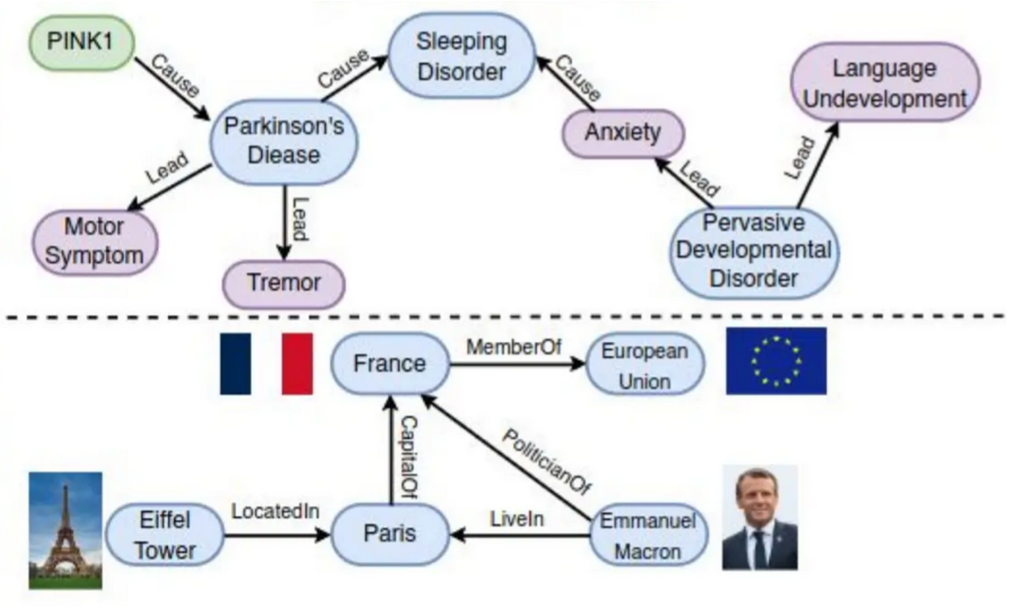
Source: GraphRAG is All You Need? LLM & Knowledge Graph
The difference between vector- and graph-based RAG is that vector databases represent data as high-dimensional vectors to measure similarity, while knowledge graphs represent that data as a map of connections.
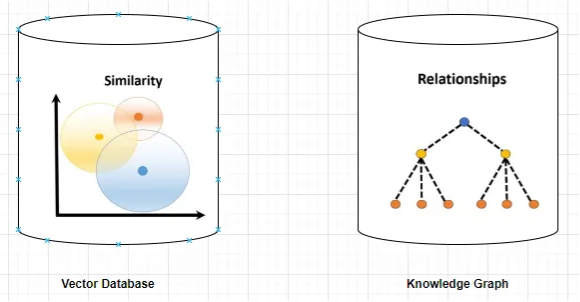
Source: Implement RAG with Knowledge Graph and Llama-Index
Why is RAG important?
If you have no need to search or analyze proprietary data when you use an LLM and you aren’t concerned about getting outdated or hallucinated information, then RAG probably won’t blow your mind.
That said, the significance of RAG is that it makes LLMs even more powerful and amazing by allowing them to interact with your data and respond with information that is up-to-date, accurate, and relevant to your search and query needs.